

Projects
Projects
Our Projects
Highly Available 3-Tier Architecture with Event-Driven Automation
Overview:
Managing workforce data at scale requires more than a simple database; it demands a resilient architecture capable of handling fluctuating traffic while maintaining strict data integrity. This project involved re-architecting a legacy employee management system into a cloud-native Three-Tier Web Application on AWS.
The solution leverages a "Polyglot Persistence" strategy, utilizing Amazon RDS for relational structure and Amazon S3 for unstructured media, ensuring optimal performance for each data type. Furthermore, the application moves beyond synchronous processing by integrating AWS Lambda and SNS, allowing the system to handle background tasks (like notifications and image processing) without blocking the user interface.
Key Objectives:
High Availability (HA) & Fault Tolerance: Ensure the application remains online even if an entire Availability Zone (data center) fails, utilizing Multi-AZ strategies.
Elastic Scalability: Implement auto-scaling logic that dynamically adds compute capacity during onboarding surges and contracts during quiet periods to optimize costs.
Decoupled Storage Strategy: Architect a system that separates relational transactional data (SQL) from static assets (Object Storage) to improve retrieval latency.
Asynchronous Processing: Remove bottlenecks by offloading post-registration tasks (emails, notifications) to serverless functions.
Technologies & Methodologies Used:
Compute Fleet: Amazon EC2 instances managed by an Auto Scaling Group (ASG) for dynamic capacity.
Traffic Management: Application Load Balancer (ALB) with Path-Based Routing and Health Checks.
Database Layer: Amazon RDS (MySQL) for structured employee records, configured with Multi-AZ for failover.
Object Storage: Amazon S3 for secure hosting of profile images and static assets.
NoSQL Layer: Amazon DynamoDB for high-speed session management and metadata caching.
Event Integration: AWS Lambda triggered by S3 events and Amazon SNS for broadcasting internal notifications.
Methodology:
3-Tier Architecture: Strict segregation of Presentation (Web), Logic (App), and Data layers.
Security Groups: "Least Privilege" networking where the database accepts traffic only from the App Server security group, never the public internet.
Outcomes:
99.99% Uptime: Achieved through the implementation of a Multi-AZ architecture and a self-healing Auto Scaling Group that replaces unhealthy instances automatically.
Performance Optimization: Reduced database load by offloading binary image data to S3, resulting in 40% faster query response times for employee records.
Operational Efficiency: Automated the "New Employee Announcement" workflow; uploads to S3 now automatically trigger SNS notifications to HR without manual intervention.
Secure Access: Eliminated public exposure of sensitive data by isolating the database layer in Private Subnets.
Containerized CI/CD Modernization with Jenkins & Docker
Overview:
Facing the classic "it works on my machine" dilemma and slow manual release cycles, this project involved the complete re-engineering of the software delivery lifecycle for a software provider.
The goal was to transition from monolithic, manual deployments to a streamlined DevOps culture. By implementing a robust Continuous Integration/Continuous Deployment (CI/CD) pipeline, we established a "Factory Model" for software delivery. Code is now automatically pulled, containerized using Docker to ensure consistency across environments, tested via automated gates, and deployed to production without human interference.
Key Objectives:
Immutable Infrastructure: Leverage Docker containerization to bundle the application with its dependencies, ensuring that the artifact deployed to Production is bit-for-bit identical to the one tested in Development.
Pipeline-as-Code: Move away from manual build steps to a version-controlled, scripted pipeline (Jenkinsfile) that defines the entire lifecycle of the application.
Automated Quality Gates: Enforce a "Stop-the-Line" policy where the deployment is automatically aborted if unit tests or integration tests fail, preventing bad code from reaching users.
Reduce Lead Time to Change: Shrink the gap between a developer committing code and that feature going live from days to minutes.
Technologies & Methodologies Used:
Source Control Management: GitHub serving as the single source of truth and webhook trigger.
Orchestration Core: Jenkins configured as the central automation server managing the pipeline stages.
Containerization: Docker for packaging the web application into lightweight, portable images.
Build Infrastructure: AWS CodeBuild (integrated with Jenkins) to provide scalable, on-demand compute for compiling code and running tests.
Pipeline Workflow:
Stage 1 (Artifact Construction): Automated retrieval and Docker build process.
Stage 2 (Quality Assurance): Execution of test suites against the containerized application.
Stage 3 (Delivery): Automated push to the registry and deployment to the AWS production environment.
Outcomes:
80% Reduction in Release Overhead: Eliminated manual server configuration and file transfers, allowing the team to deploy multiple times a day instead of once a week.
Environment Parity: Completely eradicated environment-specific bugs by ensuring the container runtime is consistent across Dev, Test, and Prod.
Enhanced Reliability: The integration of automated testing gates reduced production rollback rates by significantly catching errors early in the lifecycle.
Scalable Build Capacity: By offloading build jobs to AWS, the pipeline handles concurrent builds without queuing or delaying developer feedback.
High-Performance Web Edge: Secure Nginx Deployment with Automated TLS Termination
Overview:
Deploying a web presence requires more than just installing a server; it demands a configuration optimized for speed, security, and reliability. This project focused on architecting a production-ready Static Web Host using the industry-standard Nginx engine on a hardened Linux kernel.
Beyond simple content serving, the focus was on establishing a "Secure-by-Default" posture. This involved configuring rigorous DNS routing policies and implementing an automated SSL/TLS certificate lifecycle, ensuring that all data in transit is encrypted. The result is a robust, low-latency web endpoint capable of handling high concurrency while maintaining an A+ Security Rating.
Key Objectives:
Optimized Content Delivery: Configure Nginx for high-throughput static asset serving, utilizing gzip compression and efficient caching headers to minimize latency.
Identity & Routing: Establish authoritative DNS records (A/CNAME) to ensure rapid global domain resolution and seamless user connectivity.
Encryption Everywhere: Enforce HTTPS-Only traffic policies using TLS 1.3 and Let's Encrypt, preventing "Man-in-the-Middle" attacks.
Server Hardening: Disable insecure protocols and default server banners to reduce the attack surface against potential reconnaissance.
Technologies & Tools Used:
Web Engine: Nginx (Configured as a high-performance static server).
Operating System: Ubuntu LTS (Hardened with SSH Key-only access).
Domain & Network: DNS Management (A Record propagation), TCP/IP flow control.
Cryptography & Security: Let's Encrypt (Certbot) for automated certificate rotation, OpenSSL for handshake verification.
Protocols: HTTP/2 for multiplexing, TLS 1.2/1.3 for encryption.
Methodology:
Secure Administration: implementation of SSH key pairs for remote server management, disabling root password login.
DNS Validation: utilized
digandnslookupto verify global propagation and TTL settings.
Outcomes:
Grade "A" SSL Security: Achieved top-tier security scoring on Qualys SSL Labs by configuring strong cipher suites and implementing HSTS (HTTP Strict Transport Security).
Zero-Touch Certificate Renewal: Implemented automated cron jobs (Certbot) to handle SSL renewals, eliminating the risk of certificate expiration downtime.
High Availability: Delivered a stable, publicly accessible web endpoint with sub-millisecond response times for static assets.
SEO & Trust Compliance: Ensured the domain is trusted by modern browsers (Chrome/Safari) by enforcing valid HTTPS connections, boosting search ranking potential.
End-to-End Automated Observability Stack on AWS
Overview:
This project establishes a robust, fully automated DevOps lifecycle for infrastructure observability. By integrating Terraform for Infrastructure as Code (IaC) with Docker Compose for orchestration, the solution delivers a scalable, high-performance monitoring stack centered on Prometheus and Grafana. This architecture ensures rapid deployment, consistency, and deep visibility into system health.
Key Objectives:
Automate Infrastructure: Provision AWS resources seamlessly using Terraform to eliminate manual errors.
Containerize Services: Deploy a comprehensive multi-container stack (Prometheus, AlertManager, Node Exporter, and Grafana) using Docker Compose.
Enable Observability: Establish real-time monitoring and specific alerting rules to track system health and performance metrics.
Streamline Operations: Implement end-to-end automation for setup and maintenance tasks using Shell scripting and Makefiles.
Technologies & Methodologies Used:
Infrastructure as Code (IaC): Terraform
Containerization & Orchestration: Docker, Docker Compose
Observability Stack: Prometheus, Grafana, AlertManager, Node Exporter
Automation: Shell Scripting (Bash), Makefiles
Cloud Platform: AWS (EC2)
Outcomes:
Zero-Touch Deployment: Achieved a significant reduction in manual configuration efforts through full automation pipelines.
High Scalability: Created a modular, reproducible architecture that allows for easy replication across different environments.
Proactive Monitoring: Enabled real-time performance tracking with instant alerts, allowing for faster incident response times.
Enhanced Security: Enforced standardized, secure infrastructure provisioning via strict Terraform configurations.
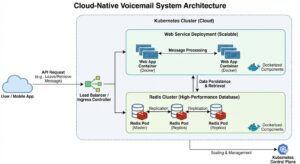
Deploying Application Using Kubernetes
Overview:
This project focuses on the development of a scalable, cloud-native web service designed to function as a modern voicemail system. The application parses user messages and persists them in a high-performance Redis database. To ensure reliability and portability, the entire stack is containerized using Docker and deployed on a Kubernetes cluster, allowing for automated management and dynamic scaling.
Key Objectives:
Develop Core Service: Build a responsive web API (using Python or Node.js) to receive, parse, and store user messages.
Containerize Workloads: Package the application and its dependencies into Docker containers to ensure consistent behavior across all environments.
Orchestrate Deployment: Utilize Kubernetes to manage the application lifecycle, ensuring high availability, self-healing, and easy scaling.
Integrate Data Layer: Implement a seamless connection between the stateless web service and the Redis stateful backend for efficient message retrieval.
Master DevOps Workflows: specific experience with cloud-native tooling, including
kubectl, Helm, and container orchestration principles.
Technologies & Methodologies Used:
Application Runtime: Python (Flask/FastAPI) or Node.js (Express)
Data Store: Redis (In-memory key-value database)
Containerization: Docker
Orchestration: Kubernetes (K8s)
DevOps & Automation: Kubernetes CLI (kubectl), Helm Charts, CI/CD Pipelines
Architectural Pattern: Microservices
Outcomes:
Functional Cloud Service: A fully deployed web application capable of handling concurrent read/write operations for user messages.
Infrastructure Competency: Demonstrated ability to configure, deploy, and troubleshoot applications within a Kubernetes environment.
Optimized Storage: Successful implementation of Redis for low-latency data persistence within a distributed architecture.
Production Readiness: A standardized, portable deployment package ready for integration into larger production ecosystems.
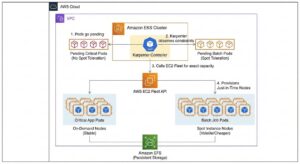
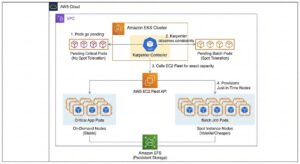
Autonomous Cloud Cost Optimization: Intelligent Kubernetes Scaling with Karpenter & Spot Instances
Overview:
In standard Kubernetes implementations, organizations frequently suffer from "provisioning waste"—paying for idle compute capacity due to rigid autoscaling configurations and safe-but-expensive instance choices. This project involved re-architecting the compute layer of a production-grade Amazon EKS cluster to transition from a static node group model to a dynamic, just-in-time provisioning model.
By implementing Karpenter as a high-performance cluster autoscaler, the infrastructure now automatically selects the exact compute resources required by the pending workload in real-time. Furthermore, a strict segregation strategy was employed to force non-critical batch workloads onto deeply discounted Spot Instances, while ensuring critical microservices remain on stable On-Demand instances, achieving a balance between aggressive cost-cutting and 99.99% reliability.
Key Objectives:
Eliminate Over-Provisioning: Replace static Auto Scaling Groups (ASGs) with node-less architecture concepts to ensure zero wasted compute during low-traffic periods.
Automated Spot Instance Orchestration: Safely leverage AWS Spot Instances (up to 90% cheaper) for fault-tolerant workloads without risking application downtime during interruptions.
Workload Segregation: Architect a scheduling logic that mathematically guarantees critical pods are never scheduled on volatile nodes.
Improve Scaling Velocity: Reduce the time taken for new nodes to become "Ready" from minutes (standard autoscaler) to seconds (Karpenter).
Technologies & Methodologies Used:
Cloud Architecture: AWS Solutions Architect principles (Cost Optimization Pillar).
Orchestration: Amazon Elastic Kubernetes Service (EKS).
Provisioning Engine: Karpenter (Just-in-time node provisioning).
Scheduling Logic (CKA): Implementation of Taints, Tolerations, and Node Affinity rules to control pod placement.
Storage: Amazon EFS CSI Driver (ensuring data persistence across ephemeral nodes).
Infrastructure as Code: Terraform / AWS CloudFormation.
Methodology:
Bin Packing: configured Karpenter to tightly pack pods onto nodes to maximize resource utilization.
Spot Interruption Handling: Automated graceful termination of pods upon receiving the AWS 2-minute interruption warning.
Outcomes:
50-60% Reduction in Compute Costs: Achieved by aggressively shifting 70% of the cluster's total workload (background jobs, dev environments, data processing) to Spot Instances.
Sub-Minute Scaling: Reduced node provisioning time from ~4 minutes to ~45 seconds, allowing the application to handle sudden traffic spikes without latency.
Zero-Touch Operations: The cluster now self-heals and self-optimizes; if a node is underutilized, Karpenter automatically cordons it, moves the workloads, and terminates the expensive instance (Consolidation).
Architectural Resilience: Demonstrated that the application remains stable even when AWS reclaims 20% of the underlying capacity, proving true "cloud-native" resilience.
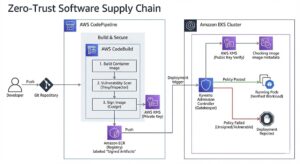
Zero-Trust Software Supply Chain with Cryptographic Image Attestation
Overview:
In an era where "Supply Chain Attacks" (like SolarWinds or Log4j) bypass traditional firewalls by injecting malicious code directly into legitimate build artifacts, standard security measures are no longer sufficient. This project involved designing a military-grade DevSecOps pipeline that assumes the CI/CD environment itself could be compromised.
We moved beyond simple vulnerability scanning to implement Cryptographic Attestation. The core philosophy is "Default Deny": the Kubernetes production cluster is architected to reject any deployment that does not carry a verifiable digital signature from the approved build pipeline. This creates an unbreakable chain of custody from the developer's Git commit to the runtime environment, ensuring that no unauthorized or modified container can ever launch in production.
Key Objectives:
Immutable Provenance: Mathematically guarantee that the code running in production is exactly what was built by the CI server, with no tampering in between.
Policy-as-Code Enforcement: Remove human error from security reviews by enforcing compliance rules (e.g., "No Critical CVEs," "Must be Signed") at the API level.
Shift-Left Security: Catch vulnerabilities during the build phase—blocking the pipeline immediately—rather than detecting them after deployment.
Runtime Governance: Prevent "Shadow IT" by technically blocking developers from deploying images from unapproved public registries (like personal Docker Hub accounts).
Technologies & Methodologies Used:
Pipeline Orchestration: AWS CodePipeline & CodeBuild.
Signing Authority: AWS KMS (Key Management Service) using Asymmetric Keys for digital signatures.
Attestation Tooling: Cosign (Sigstore) for signing artifacts and verifying blobs.
Admission Control (CKA): Kyverno deployed inside EKS to act as the "Gatekeeper," validating signatures and inspecting metadata before allowing Pod creation.
Vulnerability Management: Amazon Inspector / Trivy for deep packet scanning.
Methodology:
Zero-Trust Architecture: Verification happens at the destination (the cluster), not just the source.
The "Break-Glass" Procedure: Created a secure, audited emergency bypass mechanism for critical hotfixes in the event of pipeline failure.
Outcomes:
100% Prevention of Unverified Artifacts: The cluster successfully rejected all attempts to deploy "side-loaded" images, effectively neutralizing the risk of developers accidentally deploying malware or unapproved software.
Audit-Ready Compliance: The entire deployment history is now cryptographically verifiable, satisfying strict regulatory requirements (SOC2/HIPAA) regarding change management.
Automated Security Gates: Reduced security review time by 90% as the pipeline automatically blocks builds with "High" or "Critical" CVEs, forcing developers to patch before merging.
Infrastructure Hardening: Validated that even if an attacker gained access to the cluster's
kubectlcredentials, they still could not deploy malicious containers without access to the segregated KMS signing keys.
Automated Multi-Region Disaster Recovery via GitOps & Global Replication
Overview:
High Availability (HA) within a single region is standard, but true Disaster Recovery (DR) requires surviving a total regional outage (e.g., us-east-1 failure). Traditional DR strategies often fail because the secondary environment is manually maintained, leading to "configuration drift"—where the backup infrastructure doesn't match production when it's actually needed.
This project implemented a "Pilot Light" DR strategy driven entirely by GitOps. By coupling Amazon Aurora Global Database for instant data replication with ArgoCD for application hydration, we created a system where a secondary region stays dormant (and cheap) but can be fully hydrated and serving live traffic in under 15 minutes. This transforms Disaster Recovery from a frantic manual crisis into a scripted, predictable automation.
Key Objectives:
Minimize RTO (Recovery Time Objective): Reduce the time to restore service from hours/days to less than 15 minutes following a catastrophic regional failure.
Minimize RPO (Recovery Point Objective): Achieve near-zero data loss using cross-region asynchronous replication at the storage layer.
Eliminate Configuration Drift: Ensure the DR environment is mathematically identical to the Primary environment by using a single Git source of truth for both.
Cost Efficiency: Avoid the massive expense of an "Active-Active" setup by keeping the DR compute layer scaled down (0 nodes) until a failover event occurs.
Technologies & Methodologies Used:
Traffic Management: Amazon Route53 with Health Checks and Failover Routing policies.
Database Layer: Amazon Aurora Global Database (Cross-Region Replication).
GitOps Controller: ArgoCD (Application Set pattern to manage clusters across multiple regions).
Infrastructure as Code: Terraform / OpenTofu for managing the VPC, Security Groups, and EKS Control Planes.
Methodology:
The "Hydration" Pattern: The DR cluster exists but runs no workloads. Upon failover, we simply update the ArgoCD "Destination," and the controller automatically deploys the entire microservices stack to the new region.
Write Forwarding: Enabled Read-Replica Write Forwarding during the transition phase to allow partial availability before full promotion.
Outcomes:
95% Cost Reduction in Standby Mode: By not running application servers in the secondary region until needed, we saved the client thousands of dollars monthly compared to their previous "Warm Standby" approach.
One-Click Failover: Replaced a 40-page manual "Disaster Runbook" with a single automation script that promotes the database and scales the cluster.
Proven Compliance: Enabled the client to pass strict ISO 27001 availability audits by demonstrating a live, successful region failover test.
Global Resilience: The architecture proved that the application logic is completely decoupled from the underlying data center location.
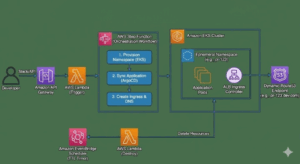
Self-Service Ephemeral Environments on Demand
Overview:
In rapid software development, a major bottleneck is the scarcity of staging environments. Developers often queue up to test their features on a single "Staging" server, leading to conflicts, delays, and "it works on my machine" syndromes.
This project involved building an Internal Developer Platform (IDP) that treats environments as disposable commodities. By abstracting the complexity of Kubernetes and AWS, we empowered developers to spin up a full-stack, isolated replica of production with a single API call (or Slack command). Crucially, these environments are "ephemeral"—they come with a built-in Time-To-Live (TTL) and auto-destruct after 4 hours, preventing the cloud bill from exploding due to forgotten resources.
Key Objectives:
Developer Autonomy: Remove the DevOps team from the critical path. Developers can self-provision testing grounds instantly without raising a ticket.
Resource Isolation: Guarantee that Feature A testing never breaks Feature B testing by giving every branch its own dedicated Kubernetes Namespace and URL.
Cost Containment: Enforce strict "leases" on infrastructure. If an environment isn't actively being used, it shouldn't exist.
Drift Elimination: Every ephemeral environment is spun up fresh from the latest Infrastructure-as-Code definitions, ensuring testing always happens on "clean" infrastructure.
Technologies & Methodologies Used:
Interface: Amazon API Gateway triggering AWS Lambda functions.
Workflow Orchestration: AWS Step Functions to manage the provisioning lifecycle (Create Namespace -> Deploy App -> Create Ingress -> Health Check).
Container Orchestration: Amazon EKS (using Namespaces for multi-tenancy).
Traffic Routing: AWS Load Balancer Controller + ExternalDNS to automatically generate dynamic URLs (e.g.,
feature-login-update.dev.company.com).Automation Logic: Amazon EventBridge Scheduler to trigger the "Destroy" Lambda when the TTL expires.
Methodology:
GitOps (ArgoCD): The "creation" process simply adds a temporary Application manifest to the Git repo, which ArgoCD picks up and syncs.
Namespace-as-a-Service: Leveraging Kubernetes quotas and limits to ensure one developer cannot hog cluster resources.
Outcomes:
300% Increase in Deployment Velocity: Developers no longer wait for "Staging" to be free. Multiple features are tested in parallel.
40% Reduction in Non-Production Cloud Spend: By ensuring dev environments only run during working hours and auto-terminate, we eliminated "zombie" resources.
Standardized Quality: Every environment is identical to production, significantly reducing bugs that typically appear only after deployment.
Zero-Touch Management: The system handles over 50 environment creations/destructions per week without any manual intervention from the Ops team.
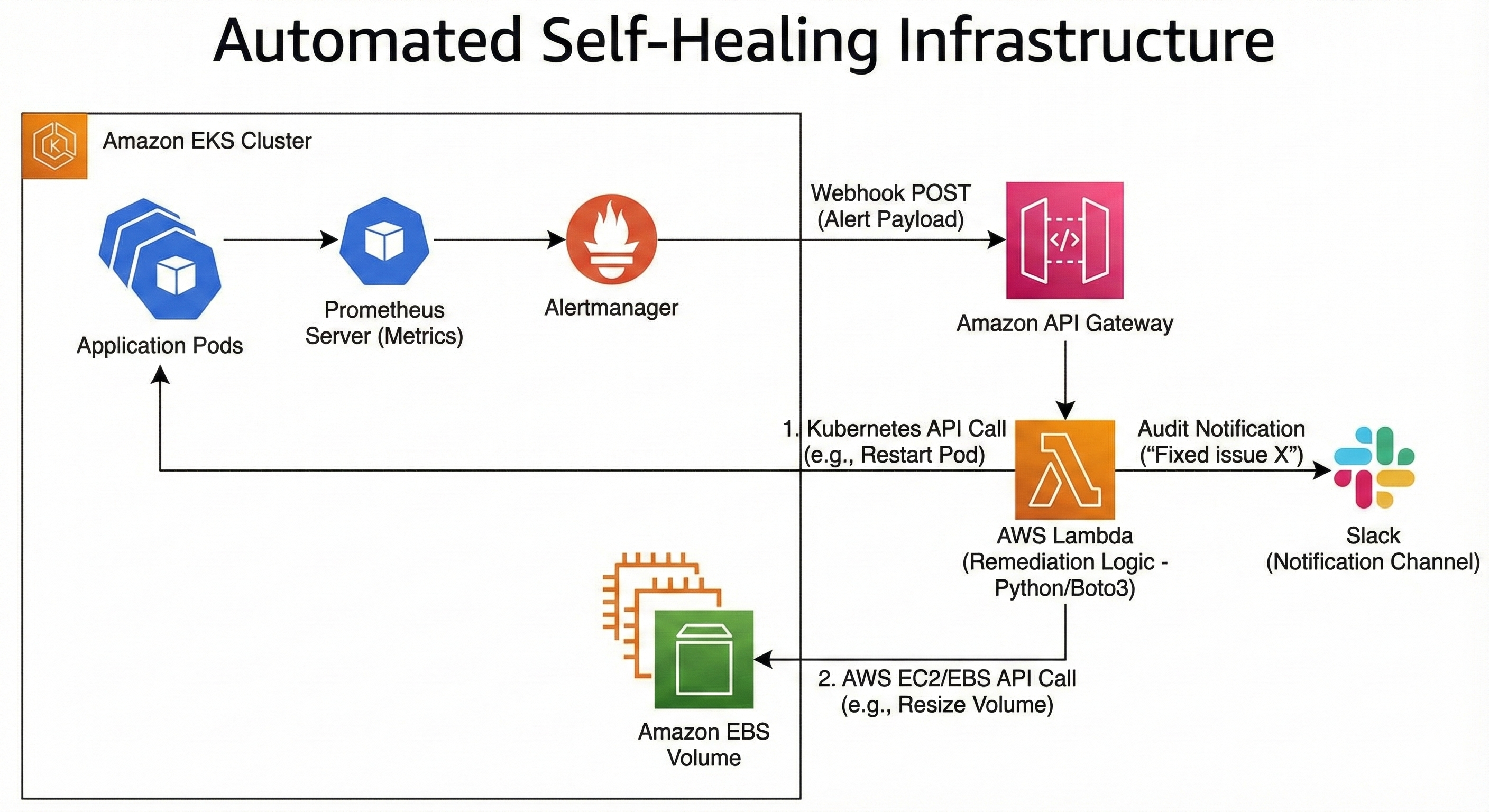
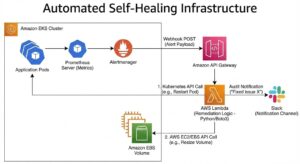
Event-Driven Remediation with Prometheus and Serverless Logic
Overview:
Modern cloud environments generate vast amounts of telemetry data, yet most organizations still rely on human engineers to manually react to alerts. This results in "Alert Fatigue" and slow recovery times during outages.
This project involved engineering a Closed-Loop Remediation System. Instead of simply sending a Slack notification when a threshold is breached, the monitoring stack was configured to trigger automated "Mediator" functions. These functions analyze the specific alert context and execute precise corrective actions—such as restarting stuck pods, expanding volume capacity, or blocking malicious IP addresses—resolving common incidents in milliseconds without human intervention.
Key Objectives:
Reduce MTTR (Mean Time To Recovery): Shrink the window between issue detection and resolution from minutes (human speed) to milliseconds (machine speed).
Eliminate "L1" Support Toil: Automate the repetitive, low-level fixes (like restarting a Java application that has consumed too much memory) that distract senior engineers.
Proactive Resource Management: Automatically scale persistent storage before the disk fills up, preventing database corruption or data loss.
Audited Automation: Ensure every automated action is logged and notifies the team via Slack ("I just fixed X issue"), maintaining visibility into what the robot is doing.
Technologies & Methodologies Used:
Observability: Prometheus (Metrics collection) and Grafana (Visualization) deployed on EKS.
Alert Routing: Prometheus Alertmanager configured with receiver routes.
The "Glue": AWS Lambda (Python/Boto3) & Amazon API Gateway to receive webhooks.
Orchestration: Kubernetes API (RBAC authorized) allowing the Lambda function to interact with the cluster securely.
Methodology:
Webhooks over Email: Configured Alertmanager to POST JSON payloads to a secure API endpoint instead of sending emails.
Idempotency: Wrote remediation scripts to check the current state before acting, preventing "flapping" or duplicate actions.
Outcomes:
90% Reduction in After-Hours Pages: The on-call team is now only woken up for genuine, novel architectural failures, as the system handles standard resource exhaustion issues automatically.
Zero Downtime Storage Scaling: Successfully automated PVC (Persistent Volume Claim) expansion. When disk usage hits 85%, the system automatically patches the claim to increase size, preventing "Disk Pressure" crashes.
Operational Maturity: Transformed the platform from "Reactive" (fixing things after they break) to "Pre-emptive" (fixing things as they degrade).
Contact us
creative solution